What Are LLM and What Are They Used For?
An LLM, or Large Language Model, is an artificial intelligence system developed to understand, generate, and respond to human language. These models are trained on large amounts of text data, which allows them to understand and generate linguistic patterns in a way that approaches human ability.
LLMs leverage deep learning techniques to process and produce language and code that is contextually relevant. Their utility stems from the ability to handle diverse linguistic tasks without specific programming for each new language or task.
Key use cases of LLMs include:
- Content generation: LLMs can draft articles, compose poetry, or generate code comments. They are programmed to understand stylistic nuances and thematic requirements, enabling them to produce high-quality content that mimics human-written text.
- Programming assistance: LLMs have significantly impacted software development by assisting in code generation and debugging. Tools like GitHub Copilot and Tabnine are trained on numerous code repositories and can help programmers by suggesting entire lines or blocks of code. This speeds up the coding process and helps reduce errors.
- Translation and localization: LLMs offer swift and accurate translations across multiple languages. Advanced LLMs handle idiomatic expressions and cultural nuances, improving the quality of translations compared to traditional machine translation systems.
- Customer support automation: LLMs streamline customer support by powering chatbots and virtual assistants capable of handling inquiries and resolving issues in real time. They interpret the customers’ queries and generate precise and helpful responses, enhancing customer satisfaction. This technology also allows for 24/7 customer service without the need for human agents at all times.
- Research and data analysis: LLMs can parse and synthesize large volumes of data to extract meaningful insights. They can review scientific literature, generate summaries, and even directly analyze datasets and generate graphs or written insights. This can help organizations and academic researchers improve productivity and carry out larger scale research. This is part of an extensive series of guides about machine learning.
How Do LLMs Work?
LLMs use a deep learning architecture known as Transformers, which focus on context within language through the attention mechanism. Attention models allow the LLM to weigh the importance of each word in a sentence relative to others, leading to more accurate interpretations and responses.
Knowing the context aids the model in generating relevant and coherent text continuations or answering questions accurately. Trainable parameters in these models can number in the billions, up to over a trillion for the largest models, allowing them to learn complex knowledge and language structures.
The training process involves adjusting these parameters to minimize the difference between predicted text and actual text, a method known as supervised learning. Once trained, LLMs can generate text, comprehend spoken or written statements, and perform translations, among many other tasks.
Which LLM Is Best? LLM Benchmarks and Leaderboards
While individual users or organizations can evaluate different LLMs on their own, it can be difficult to test them across a large amount of data and different use cases.
Formal benchmarks have been developed that can test LLMs in an automated manner to see how they compare on tasks like language understanding, content generation and coding. There are also LLM leaderboards that list many LLMs (inlcuding our own guide to LLM leaderboards), including their individual versions, with their respective benchmark scores.
Here are several benchmarks and leaderboards you can use to identify the best LLM for your use case.
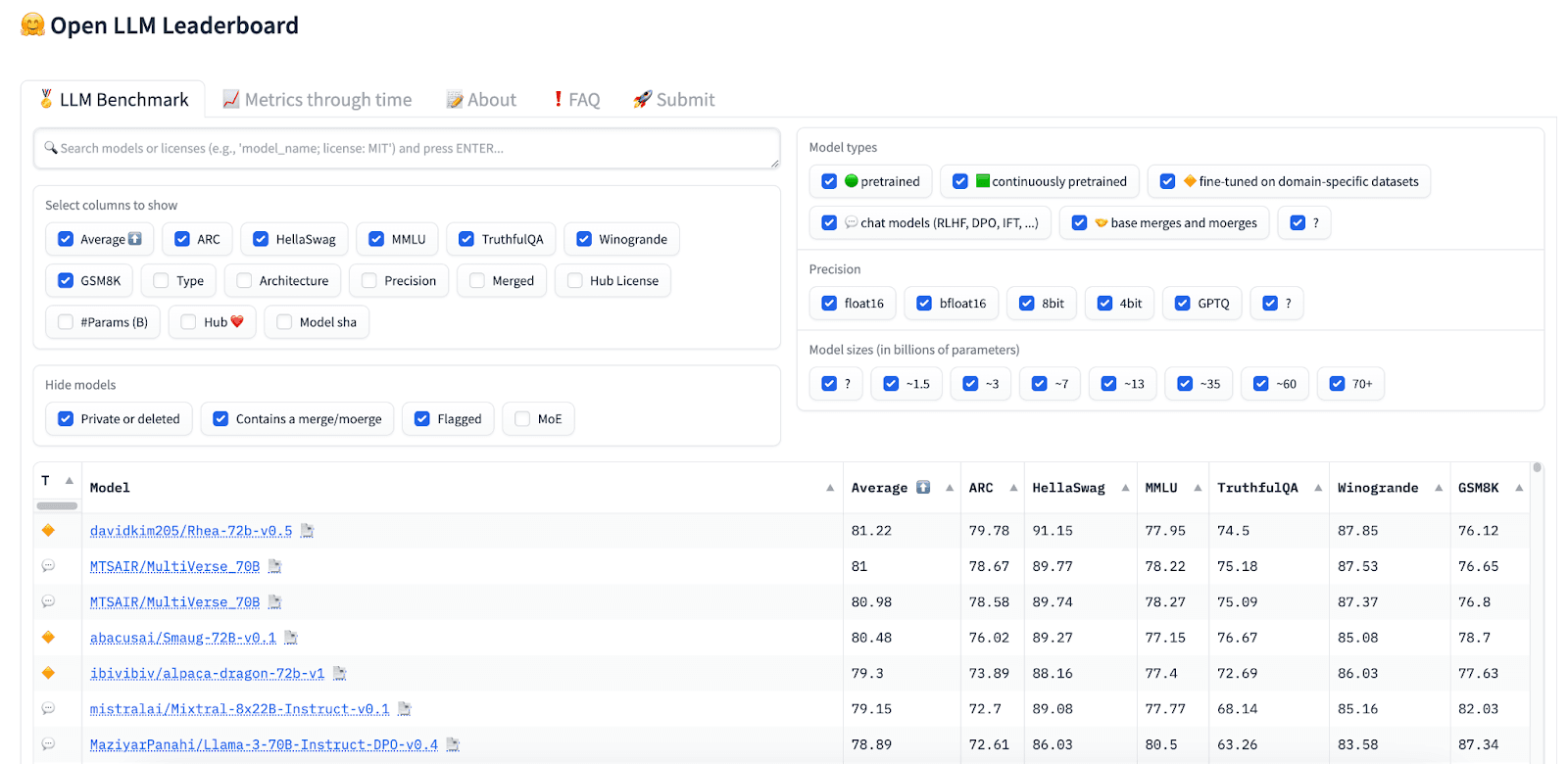
Hugging Face Open LLM Leaderboard
The Open LLM Leaderboard provides a comprehensive platform to compare the performance of LLMs based on metrics like accuracy, speed, and versatility. This benchmark helps developers understand the strengths and weaknesses of different models, guiding the selection process for specific applications. Regular updates ensure that the evaluations reflect the latest advancements in LLM technology.
Direct link: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
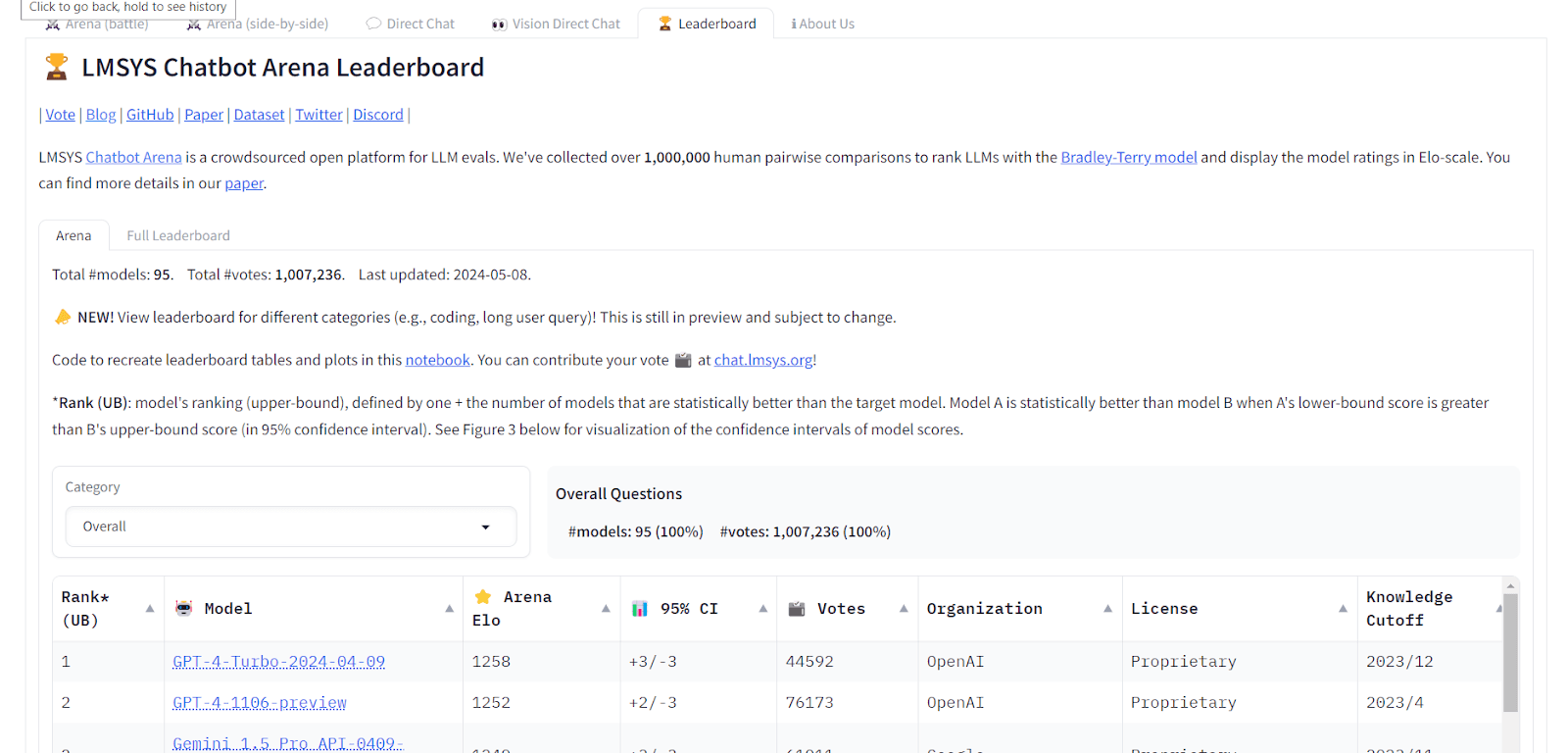
LMSYS Chatbot Arena
Chatbot Arena serves as a competitive testing ground where different LLM-powered chatbots are evaluated based on their conversational abilities, problem-solving skills, and user engagement. It is based on the Bradley-Terry Human Pairwise Comparisons benchmark, which provides insights into the chatbots’ performance in real-world scenarios.
Direct link: https://chat.lmsys.org/?leaderboard
MMLU Benchmark
MMLU, or Massive Multitask Language Understanding Benchmark, assesses the breadth of an LLM’s understanding across various academic disciplines and real-world knowledge domains. It includes multiple-choice questions from diverse subjects such as history, literature, and science, testing the comprehensiveness and depth of the model’s training.
HumanEval Benchmark
HumanEval is designed to evaluate LLMs’ programming proficiency by testing their ability to generate correct code snippets. It is based on a carefully designed dataset of human programming interview questions. This benchmark challenges models with real-world programming problems, assessing correctness and the sophistication of solutions.
ARC Benchmark
The ARC Benchmark tests LLMs on their reasoning capabilities by presenting them with a series of complex word and logic puzzles. This evaluation measures an LLM’s ability to process information, apply logical rules, and deduce correct answers, which is essential for applications in problem-solving and decision-making roles.
GSM8K Benchmark
GSM8K evaluates LLMs based on their mathematical problem-solving skills. It presents a range of grade-school math problems, from basic arithmetic to more complex algebra and geometry questions. This benchmark tests the accuracy and explanatory power of the models, ensuring they can communicate the reasoning behind their answers.
HellaSwag Benchmark
HellaSwag challenges LLMs to predict the endings of sentences in textual and video contexts, testing their ability to understand and anticipate real-world scenarios. This benchmark focuses on the model’s capacity for contextual understanding and its ability to forecast logical outcomes, critical for tasks that involve narrative understanding and content curation.
MATH Benchmark
The MATH Benchmark assesses LLMs’ capability to solve advanced mathematical problems, ranging from high school to early college levels. This testing is crucial for evaluating the models’ applicative use in educational fields, particularly in STEM, where there is a high demand for teaching aids.
SuperGLUE Benchmark
SuperGLUE is a benchmark suite designed to evaluate the sophisticated reasoning capabilities and general linguistic understanding of LLMs. It includes challenging tasks such as question answering, natural language inference, and commonsense reasoning. This rigorous testing pushes the capabilities of models to match—and possibly exceed—human performance levels.
The Smartest LLM Models in 2024: Commercial Models
Here are the commercial LLMs currently leading the charts in terms of performance benchmarks and user adoption.
For Open source models check out our Open LLM Leaderboard guide
1. OpenAI GPT-4
OpenAI’s GPT-4 is equipped with multimodal capabilities that include processing both text and image inputs to generate text outputs. It is estimated to have over 1 trillion parameters and is based on a Mixture of Experts (MoE) architecture. It demonstrates near-human performance on various professional and academic benchmarks.
Features of GPT-4:
- Multimodal capabilities: Accepts both image and text inputs, providing versatile responses across different types of data.
- Large context window: Initially launched with a context window of 32,000 tokens GPT-4 now supports 128,000 tokens, allowing it to handle user prompts with rich context and respond to questions on long documents.
- Enhanced performance on benchmarks: Achieves top scores in LLM benchmarks and human exams, surpassing previous models with its deeper understanding and reasoning.
- Iterative alignment: Enhanced through a rigorous six-month adversarial testing program, which has significantly refined its accuracy and response quality.
- Scalable architecture: Co-designed with Azure, its architecture supports extensive scalability and stable training environments.
- Safety and steerability improvements: Features improved mechanisms to ensure responses remain within safe and ethical boundaries, making it more reliable across various applications.
New features in GPT-4o:
In May, 2024, OpenAI released a new edition of GPT-4, known as GPT-4o (Omnimodel) with significantly improved capabilities:
- Multimodal input and output: GPT-4o can process any combination of text, audio, image, and video inputs, and generate text, audio, and image outputs. This allows for more natural and versatile human-computer interactions.
- Improved response time: GPT-4o responds to audio inputs in as little as 232 milliseconds, with an average response time of 320 milliseconds, similar to human conversational speed. This is a significant improvement over previous models.
- Enhanced performance in non-English languages: While maintaining high performance in English and code, GPT-4o shows substantial improvements in understanding and generating text in non-English languages.
- Cost and efficiency: GPT-4o is 2X faster and 50% cheaper in the API compared to previous models. It also offers higher message limits, making it more accessible for developers and users.
- Advanced vision and audio understanding: The model excels in tasks involving vision and audio, such as real-time translation, point-and-learn applications, and interactive conversational scenarios.
- Integrated model architecture: Unlike previous models that required separate pipelines for different modalities, GPT-4o processes all inputs and outputs through a single neural network. This integration allows it to capture more context and subtleties, such as tone and background noises, and to understand and express emotions.
- Wide availability: GPT-4o will be available to free users, with usage limits. This is the first time GPT-4 has been available to the general public at no cost.
2. Google Gemini
Google Gemini was introduced by Google DeepMind as their most advanced and general model yet. This model has been designed to be multimodal from the ground up, enabling it to seamlessly process and integrate text, code, audio, images, and video.
Features of Google Gemini:
- Multimodal capabilities: Gemini can handle a variety of data types, understanding and generating content that transcends traditional language models.
- Real-time knowledge: Unlike its competitors, Gemini does not have a “knowledge cutoff date”. It has access to Google’s search index and can respond to live events as they happen.
- Tiered model system: Gemini is offered in multiple editions, from a lightweight model with low computing requirements (currently known as Gemini Flash) to the most capable model (currently known as Gemini Pro).
- Performance: Across 30 out of 32 major benchmarks, Gemini Ultra shows superior performance, even surpassing human experts in tasks involving massive multitask language understanding (MMLU).
- Advanced reasoning: Beyond simple task execution, Gemini demonstrates deep reasoning abilities, crucial for handling complex, multi-domain problems.
- Flexible deployment: Can be deployed on cloud-based infrastructures, on-premises systems or personal devices.
- Infrastructure: Supported by Google’s latest TPUs, Gemini benefits from high-speed training and deployment capabilities.
New features in Gemini Pro 1.5:
In February, 2024, Google launched a more powerful edition of Gemini:
- Extended context window: The model supports a context window of up to 1 million tokens, significantly increasing its capacity to process and understand large amounts of information in a single prompt. This is a considerable leap from the previous 32,000-token limit.
- Enhanced long-context understanding: The model can handle extensive content such as hour-long videos, long transcripts, and large codebases. It demonstrates the ability to analyze, classify, and summarize large datasets effectively.
- Higher performance benchmarks: Gemini Pro 1.5 outperforms the previous models on 87% of relevant benchmarks.
3. Claude 3
Claude 3 is a family of three progressively advanced models: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Each model provides varying levels of intelligence, speed, and cost-effectiveness. Opus is the most capable in a variety of cognitive tasks and benchmarks, reflecting near-human comprehension and problem-solving abilities.
Features of Claude 3:
- Enhanced cognitive performance: Achieves top marks in benchmarks such as MMLU and GPQA, with superior reasoning, language, and coding skills compared to most competing models.
- Real-time processing: Capable of powering instant-response applications, such as live customer chats and data extraction, with Haiku providing the fastest performance.
- Advanced vision capabilities: Able to process and respond to a diverse range of visual information.
- Reduced refusal rate: Shows significant improvements in understanding contextual boundaries, leading to fewer unnecessary refusals.
- Responsible design: Incorporates multiple safeguards to mitigate risks such as misinformation, privacy issues, and biases.
4. Cohere Command R+
Cohere Command R+ is optimized for conversational interaction and handling long-context tasks, with a special focus on enterprise use cases. This model is designed for complex scenarios, such as retrieval augmented generation (RAG) and multi-step tool use, making it suitable for businesses ready to transition from proof of concept to full-scale production.
Features of Cohere Command R+:
- Can be deployed on-premises: A primary use case of the model is for use in on-premises deployments or within an organization’s cloud environment.
- Optimized for complex interactions: Command R+ excels in environments that require complex RAG functionalities and the use of multiple tools in sequence.
- Extended context length: Supports a maximum token length of 128k, allowing for extended conversations and more comprehensive data handling within a single session.
- Multilingual capabilities: Trained on a corpus in multiple languages, Command R+ performs well in English, French, Spanish, Italian, German, and several other languages, with added pre-training in 13 additional languages.
- Cross-lingual tasks: Capable of performing tasks such as translation and providing responses in the user’s language.
- Retrieval augmented generation: In English, Command R+ can ground its responses using document snippets, providing citations and ensuring that the generated content is accurate and sourced.
The Smartest LLM Models in 2024: Open Source Models
The following are open source models which offer performance comparable to commercial offerings, and allow much more flexibility for generative AI development.
5. Meta LLaMA 3
Meta LLaMA 3 is an open source LLM available in 8B and 70B versions, pretrained and instruction-tuned to cater to diverse applications. It provides convenient options for fine-tuning the model to specific use cases.
Features of Meta Llama 3:
- Dual model offerings: Available in 8 billion and 70 billion parameter versions, providing scalability and depth for various application needs.
- Performance: Handles language nuances, contextual understanding, and complex tasks such as translation and dialogue generation.
- Enhanced scalability and reduced refusals: Features improved scalability, significantly reduced false refusal rates, and better alignment in responses.
- Expanded training and context capacity: Trained on a dataset 7x larger than its predecessor with 4x more code, supporting an 8K context length that doubles the capacity of LLaMA 2.
6. Google Gemma
Google Gemma is a series of open models (available free but not strictly open source) that leverage the same research and technology developed for the commercial Gemini models. Available in 2B and 7B sizes, these models are designed to be lightweight and accessible, providing high performance for their size.
Features of Google Gemma:
- Lightweight and open models: Gemma is offered in two configurations, 2B and 7B.
- Framework support: Compatible with the latest Keras 3.0, Gemma models can be used interchangeably with JAX, TensorFlow, and PyTorch, facilitating easy transitions between different frameworks based on project requirements.
- Responsible AI by design: Every Gemma model is built with a strong emphasis on safety and responsibility, using curated datasets and rigorous tuning to ensure trustworthy AI solutions.
- Variants tailored for specific needs: CodeGemma focuses on coding tasks, offering robust code completion and generation, while RecurrentGemma uses recurrent neural networks for enhanced memory efficiency.
- Optimized for Google Cloud: These models are fine-tuned to perform optimally on Google Cloud, leveraging TPU optimizations to deliver high performance.
7. Mistral 7B, Mixtral 8x7B, Mixtral 8x22B
Mistral provides open source LLMs, available under the Apache 2.0 license, ensuring they can be used freely without restrictions. They are designed to provide competitive performance while maintaining cost efficiency. The following three open source models are available:
- Mistral 7B is a lightweight model with 7 billion parameters. Despite its smaller size, Mistral 7B is powerful enough to handle tasks in both English and code processing.
- Mixtral 8x7B is a sparse Mixture-of-Experts (SMoE) model, utilizing 12.9 billion active parameters out of a total of 45 billion. This structure allows the model to activate only a subset of parameters during inference, optimizing performance and computational efficiency. It excels in multiple languages and code-related tasks.
- Mixtral 8x22B is Mistral’s most advanced model, featuring 22 billion parameters in a sparse Mixture-of-Experts (SMoE) configuration. It activates 39 billion parameters out of a total of 141 billion during inference, balancing performance and resource use.
Key features of Mistral models:
- Large context window: Mistral models support a context window of 32,000 tokens (for 7B and 8x7B) and 64,000 tokens (for 8x22B).
- Customization: Easily deployable and customizable for specific use cases.
- Multilingual proficiency: Fluent in English, French, Italian, German, and Spanish, with strong capabilities in code.
- Performance: The 7B model outperforms larger models like LLaMA 2 70B in benchmarks, and larger models are competitive with state of the art commercial models.
- Native function calling: 8x7B and 8x22B are capable of calling functions and operating in JSON mode, making them suitable for complex, interactive tasks.
- Cost-effective performance: According to Mistral, 8x22B delivers a high performance-to-cost ratio, outperforming larger models like Command R+ while being 2.5 times smaller.
Mistral also offers commercial LLMs known as Mistral Small, Large, and Embed, based on the same technology.
8. Stable LM 2
Stable LM 2 12B introduces a pair of 12 billion parameter language models designed for enhanced multilingual capabilities. It is an open source model by Stability AI, makers of the widely used Stable Diffusion image generation model. Stable LM 2 features a base model and an instruction-tuned variant, both of which have been trained on a diverse multilingual dataset including text in English, Spanish, German, Italian, French, Portuguese, and Dutch.
Features of Stable LM 2 12B:
- **Multilingual design: **Trained on 2 trillion tokens across seven languages.
- Dual model availability: Includes both a base and an instruction-tuned model to cater to different needs, from general language tasks to more complex applications requiring detailed instruction following.
- Advanced functionality: The instruction-tuned model is capable of using tools and calling functions, enabling integration into retrieval RAG systems and other AI setups.
- Performance competitiveness: Demonstrates strong performance across general benchmarks, comparing favorably with larger models on zero-shot and few-shot tasks.
Building LLM Applications with Acorn
To download GPTScript visit https://gptscript.ai. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can build any application imaginable: check out tools.gptscript.ai and start building today.
See Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of machine learning.
Auto Image Crop
Authored by Cloudinary
- Auto Image Crop: Use Cases, Features, and Best Practices
- 5 Ways to Crop Images in HTML/CSS
- Cropping Images in Python With Pillow and OpenCV
AI Summarization
Authored by Acorn
- AI Summarization: How It Works and 5 Tips for Success
- AI for Summarizing Articles: How It Works & 10 Tools To Use
- 8 AI Summarization Tools to Know in 2024
Anthropic Claude
Authored by Acorn