What Is the Google Gemini API?
Google Gemini is a multi-modal large language model (LLM). It provides natural language and image processing capabilities to enable text generation, sentiment analysis, document processing, image and video analysis, and more. Using the Gemini API, developers can integrate AI functionalities into their applications without needing deep expertise in machine learning algorithms.
The Google Gemini API provides the following key features:
- Creating custom AI models: Developers can build and fine-tune models tailored to specific tasks, ensuring that the models can recognize and process unique data sets. This customization makes it easier to deploy AI solutions suited to particular production environments.
- Function calling: This feature allows the API to interpret plain language requests and map them to specific programming interfaces, enabling applications to retrieve up-to-date information from business systems and take appropriate actions.
- Searching and answering with embeddings: Text embeddings in Gemini enable the API to perform tasks like content search, question answering, content generation, and data classification. This capability allows developers to build applications that can navigate complex data structures, answer user queries, and perform specific actions based on the content and context.
- Developer resources: The Gemini API provides various tools and resources for building specialized applications. Developers can leverage tutorials and templates.
- Example agents: Google provides sample code developers can use to create advanced AI agents, such an automated code generator, a data exploration agent, and a content search agent for developing conversational search interfaces.
In this article:
- Google Gemini API Pricing
- Quick Start: Getting Started with the Gemini API
- Tutorial: Working with the Google Gemini API
Google Gemini API Pricing {#google-gemini-api-pricing}
The Google Gemini API offers two main pricing tiers:
Free of Charge
The free tier is available for all versions of the Gemini models, including Gemini 1.5 Flash, Gemini 1.5 Pro, Gemini 1.0 Pro, and text embedding 004. This tier provides limited rate limits and free access to various capabilities. For example:
- Gemini 1.5 Flash: Users can make up to 15 requests per minute and process up to 1 million tokens per minute, with no charges for input, output, or context caching for up to 1 million tokens of storage per hour.
- Gemini 1.5 Pro: Allows 2 requests per minute and 32,000 tokens per minute under the free plan, with no context caching offered.
- Gemini 1.0 Pro: Offers free usage with up to 15 requests per minute and 32,000 tokens per minute, focusing on providing text and image reasoning.
- Text embedding 004: Supports a high rate of 1,500 requests per minute without any associated input, output, or context caching costs.
Pay-as-you-Go
This model charges users according to actual usage. Rates vary significantly across different Gemini models:
- Gemini 1.5 Flash: Users can process up to 1,000 requests per minute and 4 million tokens per minute, with costs starting at $0.075 per million tokens for input processing. Additional costs apply for context caching and output processing, depending on token size.
- Gemini 1.5 Pro: Users can expect to pay $3.50 to $7.00 per million tokens for input processing and up to $21 per million tokens for output processing, with context caching available at an additional cost.
- Gemini 1.0 Pro: Charges $0.50 per million tokens for input processing and $1.50 per million tokens for output processing, with no context caching option.
- Text embedding 004: Completely free, does not offer a pay-as-you-go service tier.
Related content: Read our guide to Google Gemini Pro
Quick Start: Getting Started with the Gemini API {#quick-start-getting-started-with-the-gemini-api}
The instructions in this and the following section are adapted from the Gemini documentation. We’ll show how to get started with the Google Gemini API using the Python SDK. SDKs are also available for Node.js, Go, Dart (Flutter), and Android Swift.
Prerequisites
Before you begin, ensure that your local environment meets the following requirements:
- Python 3.9+: The Google Gemini API requires Python 3.9 or later.
- Jupyter Notebook: Although optional, using Jupyter can be helpful for running and testing your code interactively.
Step 1: Install the Gemini API SDK
The Google Gemini API SDK is part of the google-generativeai package. You can install this package using pip. This will allow you to interact with the Gemini API directly from your Python code.
pip install -q -U google-generativeai
Step 2: Authenticate
Next, you need to set up your API key to authenticate your requests to the Gemini API. You should generate this key from the Google AI Studio.
Once you have your API key, configure it as an environment variable to keep it secure. This practice is recommended over hardcoding your API key directly into your code to prevent accidental exposure.
export API_KEY=<YOUR_API_KEY>
Step 3: Initialize the Model
Before making any API calls, you need to import the google.generativeai package and configure the model. The example below demonstrates how to initialize the Gemini 1.5 Flash model, which supports both text and multimodal prompts.
import google.generativeai as genai
import os
# Configure the API key
genai.configure(api_key=os.environ["API_KEY"])
# Initialize the Gemini 1.5 Flash model
model = genai.GenerativeModel('gemini-1.5-flash')
Step 4: Make Your First Request
Now that your model is initialized, you can generate text using the API. Here’s a simple example that asks the model to write a story about an AI and magic.
# Generate text content with the model
response = model.generate_content("Write a script for the first episode of a sci-fi TV series")
# Output the generated text
print(response.text)
This code sends a prompt to the Gemini API and returns a generated story based on your input. The response contains the generated text, which you can print or use in your application.
Tutorial: Working with the Google Gemini API {#tutorial-working-with-the-google-gemini-api}
Generate Text Using the Gemini API
The Google Gemini API provides various methods for generating text, whether from a simple text prompt or a combination of text and images.
Generate Text from Text-Only Input
The simplest way to generate text using the Gemini API is by providing a single text prompt.
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content("Write a script for the first episode of a sci-fi TV series.")
print(response.text)
In this example, the prompt "Write a script…" is passed directly to the model without any additional configuration. This is known as a zero-shot approach, where the model generates text based solely on the given input without any prior examples or instructions. While this approach is simple, it might not always produce the best responses. For more complex tasks, you might want to explore one-shot or few-shot prompting, where you provide examples or guidelines to improve the output.
Generate Text from Text-and-Image Input
The Gemini API also supports multimodal inputs, allowing you to generate text based on a combination of text and images. This can be particularly useful when the context involves visual elements that need to be described or analyzed.
import PIL.Image
model = genai.GenerativeModel("gemini-1.5-flash")
toyota = PIL.Image.open("toyota.jpg")
response = model.generate_content(["Tell me about this car", toyota])
print(response.text)
In this snippet, the model is provided with both a text prompt ("Tell me about this car") and an image (toyota.jpg). The API processes the image and generates text that describes the content. Multimodal inputs can be fine-tuned with additional instructions or steps depending on the complexity of the task.
Generate a Text Stream
For scenarios where you need faster interactions, the Gemini API supports text streaming. This allows you to start receiving parts of the response before the entire generation process is complete, which can be beneficial for real-time applications.
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content("Write a fairytale about an enchanted kettle.", stream=True)
for chunk in response:
print(chunk.text)
print("_" * 80)
The stream=True parameter enables streaming, and the response is processed in chunks as the model generates the text. This approach is particularly useful in applications where immediate feedback is necessary, such as in chatbots or interactive systems.
Build an Interactive Chat
The Gemini API can also be used to create interactive chat experiences. This feature is suitable for applications like customer support, tutoring systems, or any scenario that requires a back-and-forth conversation.
model = genai.GenerativeModel("gemini-1.5-flash")
chat = model.start_chat(
history=[
{"role": "user", "parts": "Hi there"},
{"role": "model", "parts": "Nice to meet you. How can I help you?"},
]
)
response = chat.send_message("I have 3 cats in my room.")
print(response.text)
response = chat.send_message("How many paws are there in my room?")
print(response.text)
In this example, the chat history is initialized with a greeting from both the user and the model. The send_message method allows the conversation to continue, with the model generating responses based on the ongoing dialogue. This can be expanded into more complex interactions depending on the needs of your application.
Configure Text Generation
The Gemini API offers several configuration options to customize how text is generated. You can control the length, randomness, and stopping conditions of the generated content using GenerationConfig.
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content(
"Write a fairytale about an enchanted kettle.",
generation_config = genai.types.GenerationConfig(
candidate_count = 1,
stop_sequences = ["x"],
max_output_tokens = 300,
temperature = 1.0,
),
)
print(response.text)
Here, GenerationConfig is used to specify:
-
candidate_count: The number of response variations to generate (only 1 is allowed currently). -
stop_sequences: The sequences of characters that will stop text generation. -
max_output_tokens: The maximum number of tokens (words or punctuation marks) in the response. -
temperature: Controls the randomness of the output, with higher values leading to more creative responses.
These settings allow for fine-tuning the model’s output, making it more suited to specific tasks or requirements. For example, lowering the temperature might be useful for generating more predictable, fact-based content, while a higher temperature could be used for creative writing.
Document Processing Capabilities with the Gemini API
The Google Gemini API offers document processing capabilities, particularly with the Gemini 1.5 Pro and 1.5 Flash models. These models can handle up to 3,600 pages per document, with each page equating to approximately 258 tokens. Documents must be in PDF format, and while there is no explicit pixel limit, the resolution is managed to optimize performance.
For optimal results, it’s essential to prepare your documents by ensuring they are correctly oriented and free of blurriness. Additionally, if you are working with single-page documents, you should place the text prompt immediately after the page.
Uploading Documents with the File API
To process documents, you first need to upload them using the File API. This API can handle files of any size, making it ideal for large documents that exceed the 20 MB limit imposed by other methods. The File API also allows for up to 20 GB of storage per project, with individual files stored for 48 hours.
Here’s how you can upload a PDF document:
import google.generativeai as genai
!curl -o gemini.pdf https://storage.googleapis.com/cloud-samples-data/generative-ai/pdf/2403.05530.pdf
sample_file = genai.upload_file(path = "gemini.pdf", display_name = "Gemini 1.5 PDF")
print(f"Uploaded file '{sample_file.display_name}' as: {sample_file.uri}")
The upload_file function stores the document and provides a URI, which you can reference in subsequent API calls.
Verifying Upload and Retrieving Metadata
After uploading, you can verify that the file was successfully stored and retrieve its metadata:
file = genai.get_file(name = sample_file.name)
print(f"Retrieved file '{file.display_name}' as: {sample_file.uri}")
This step ensures that your file is correctly uploaded and accessible for further processing.
Prompting the API with Uploaded Documents
Once your document is uploaded, you can use it in conjunction with a text prompt to generate content:
model = genai.GenerativeModel(model_name = "gemini-1.5-flash")
response = model.generate_content([sample_file, "Please provide a summary of this document as a list of bullets."])
print(response.text)
This example prompts the Gemini API to summarize the content of the uploaded document.
Handling Multiple Documents
You can also upload multiple documents and process them together:
sample_file_2 = genai.upload_file(path = "example-1.pdf")
sample_file_3 = genai.upload_file(path = "example-2.pdf")
prompt = "Provide a summary of the main differences between the abstracts for each thesis."
response = model.generate_content([prompt, sample_file, sample_file_2, sample_file_3])
print(response.text)
This approach is useful when you need to compare or aggregate information across several documents.
Managing Uploaded Files
You can list all the files you’ve uploaded:
for file in genai.list_files():
`print(f"{file.display_name}, URI: {file.uri}")`
And you can manually delete files before their automatic deletion after 48 hours:
genai.delete_file(sample_file.name)
print(f'Deleted file {sample_file.uri}')
This functionality helps you manage your file storage effectively while using the Gemini API.
Code Execution With the Gemini API
The Google Gemini API includes a feature called code execution, which enables the model to generate, execute, and refine Python code as part of its response. This is useful for applications that require complex problem-solving, such as performing calculations, processing data, or running simulations. The model can use code execution to iteratively improve its output based on the results of the code it generates, making it a tool for dynamic, code-driven applications.
Step 1: Enable Code Execution on the Model
First, you’ll need to initialize the Gemini API model with the code execution capability enabled. The following Python code demonstrates how to do this:
import os
import google.generativeai as genai
genai.configure(api_key = os.environ['API_KEY'])
model = genai.GenerativeModel(
model_name = 'gemini-1.5-pro',
tools = 'code_execution'
)
response = model.generate_content((
'Tell me the sum of the first 40 odd numbers.'
'Generate and run code for this calculation, and make sure it includes all 40.'
))
print(response.text)
In this example, the model is instructed to calculate the sum of the first 40 odd numbers. The Gemini API generates the necessary Python code, executes it, and then returns the result.
Step 2: Understanding the Generated Code
When the API is asked to solve a problem, it generates Python code to achieve the desired outcome. Here’s an example of what the generated code might look like:
sum = 0
for i in range(1, 80, 2):
sum = sum + i
print(f'{sum=}')
In this code, the for loop iterates over the range of numbers starting from 1 up to 79 (inclusive) with a step of 2. This ensures that only odd numbers are considered because starting from 1, adding 2 each time results in the sequence 1, 3, 5, 7, ..., 79.
Within the loop, the current number i is added to the sum variable in each iteration.
Output Example:
The sum of the first 40 odd numbers is: 1600
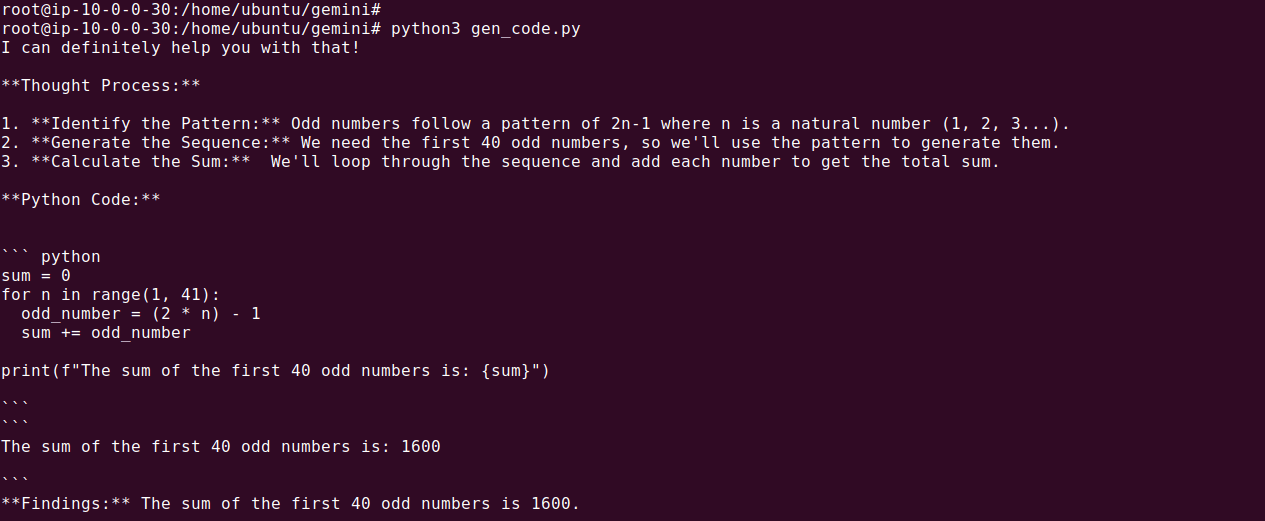
Step 3: Enable Code Execution on the Request
If you prefer, you can also enable code execution directly within the generate_content request, as shown below:
response = model.generate_content(
('Tell me the sum of the first 40 odd numbers? '
'Generate and run code for this calculation, and make sure it includes all 40.'),
tools='code_execution'
)
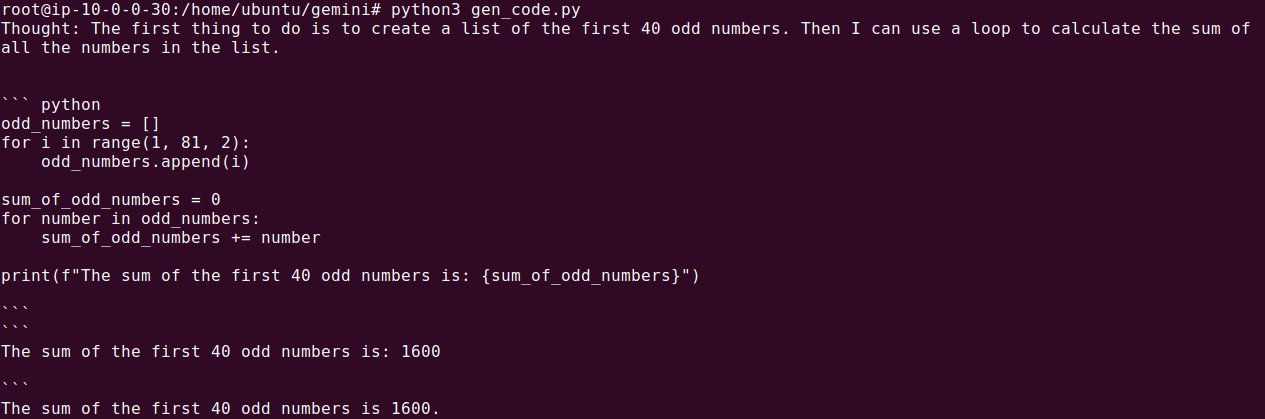
This method achieves the same result but gives you flexibility in configuring code execution on a per-request basis.
Step 4: Use Code Execution in Chat
You can also integrate code execution within an interactive chat session:
chat = model.start_chat()
response = chat.send_message((
'Tell me the sum of the first 40 odd numbers? '
'Generate and run code for this calculation, and make sure it includes all 40.'
))
print(response.text)
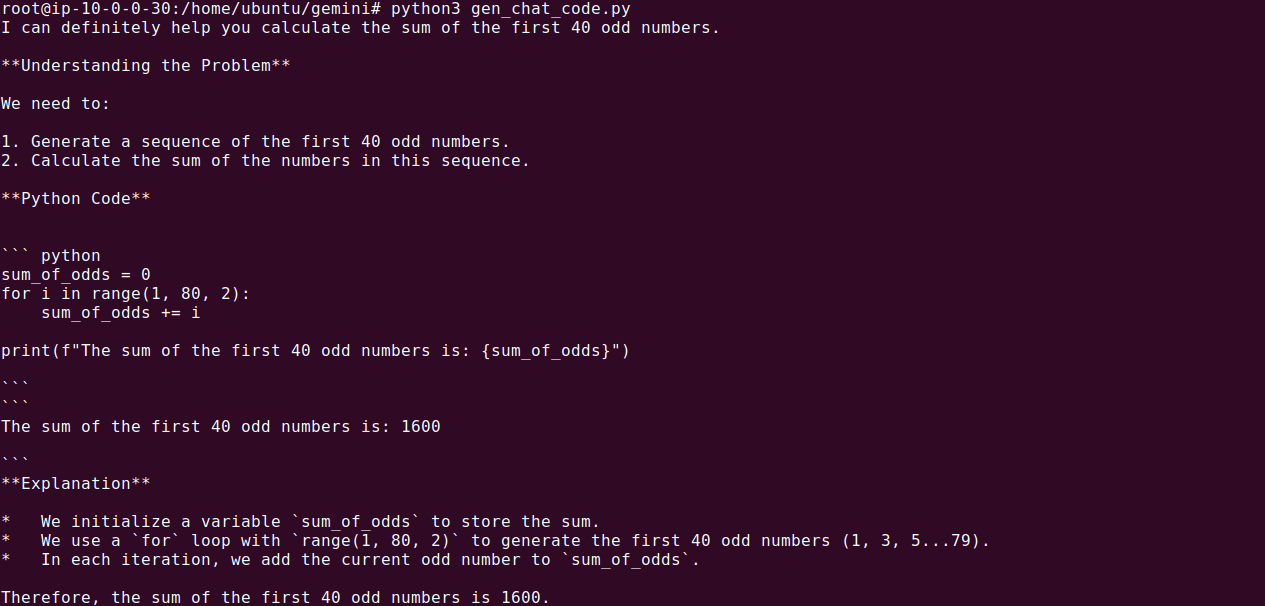
In this scenario, the code execution is part of an ongoing conversation, making it suitable for applications like tutoring systems or interactive coding assistants.
Build LLM Applications with Gemini and Acorn
Visit https://gptscript.ai to download GPTScript and start building today. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can create any application imaginable: check out tools.gptscript.ai to get started.